
Module – 1 : Why should you learn to write programs, Variables, expressions and statements, Conditional execution, Functions –8Hours
Module – 2 : Iteration, Strings, Files –8 Hours
Module – 3 : Lists, Dictionaries, Tuples, Regular Expressions–8 Hours
Module – 4 : Classes and objects, Classes and functions, Classes and methods–8 Hours
Module – 5 : Networked programs, Using Web Services, Using databases and SQL–8 Hours
Course objectives: This course will enable students to
Learn Syntax and Semantics and create Functions in Python.
Handle Strings and Files in Python.
Understand Lists, Dictionaries and Regular expressions in Python.
Implement Object Oriented Programming concepts in Python
Build Web Services and introduction to Network and Database Programming in Python.
Course outcomes: The students should be able to:
Examine Python syntax and semantics and be fluent in the use of Python flow control and functions.
Demonstrate proficiency in handling Strings and File Systems.
Create, run and manipulate Python Programs using core data structures like Lists, Dictionaries and use Regular Expressions.
Interpret the concepts of Object-Oriented Programming as used in Python.
Implement exemplary applications related to Network Programming, Web Services and Databases in Python.
Question paper pattern:
The question paper will have TEN questions. There will be TWO questions from each module. Each question will have questions covering all the topics under a module. The students will have to answer FIVE full questions, selecting ONE full question from each module.
Text Books:
1. Charles R. Severance, “Python for Everybody: Exploring Data Using Python 3”, 1st Edition, CreateSpace Independent Publishing Platform, 2016. (http://do1.drchuck.com/pythonlearn/EN_us/pythonlearn.pdf ) (Chapters 1 – 13, 15)
2. Allen B. Downey, "Think Python: How to Think Like a Computer Scientist”, 2ndEdition, Green Tea Press, 2015. http://greenteapress.com/thinkpython2/thinkpython2.pdf) (Chapters 15, 16, 17)(Download pdf files from the above links)
Reference Books:
1. Charles Dierbach, "Introduction to Computer Science Using Python", 1st Edition, Wiley India Pvt Ltd. ISBN-13: 978-8126556014
2. Mark Lutz, “Programming Python”, 4th Edition, O’Reilly Media, 2011.ISBN-13: 978-9350232873 3. Wesley J Chun, “Core Python Applications Programming”, 3rd Edition,Pearson Education India, 2015. ISBN-13: 978-9332555365
4. Roberto Tamassia, Michael H Goldwasser, Michael T Goodrich, “Data Structures and Algorithms in Python”,1stEdition, Wiley India Pvt Ltd, 2016. ISBN13: 978- 8126562176
5. Reema Thareja, “Python Programming using problem solving approach”, Oxford university press, 2017
Module – 2 : Iteration, Strings, Files –8 Hours
Module – 3 : Lists, Dictionaries, Tuples, Regular Expressions–8 Hours
Module – 4 : Classes and objects, Classes and functions, Classes and methods–8 Hours
Module – 5 : Networked programs, Using Web Services, Using databases and SQL–8 Hours
Course objectives: This course will enable students to
Learn Syntax and Semantics and create Functions in Python.
Handle Strings and Files in Python.
Understand Lists, Dictionaries and Regular expressions in Python.
Implement Object Oriented Programming concepts in Python
Build Web Services and introduction to Network and Database Programming in Python.
Course outcomes: The students should be able to:
Examine Python syntax and semantics and be fluent in the use of Python flow control and functions.
Demonstrate proficiency in handling Strings and File Systems.
Create, run and manipulate Python Programs using core data structures like Lists, Dictionaries and use Regular Expressions.
Interpret the concepts of Object-Oriented Programming as used in Python.
Implement exemplary applications related to Network Programming, Web Services and Databases in Python.
Question paper pattern:
The question paper will have TEN questions. There will be TWO questions from each module. Each question will have questions covering all the topics under a module. The students will have to answer FIVE full questions, selecting ONE full question from each module.
Text Books:
1. Charles R. Severance, “Python for Everybody: Exploring Data Using Python 3”, 1st Edition, CreateSpace Independent Publishing Platform, 2016. (http://do1.drchuck.com/pythonlearn/EN_us/pythonlearn.pdf ) (Chapters 1 – 13, 15)
2. Allen B. Downey, "Think Python: How to Think Like a Computer Scientist”, 2ndEdition, Green Tea Press, 2015. http://greenteapress.com/thinkpython2/thinkpython2.pdf) (Chapters 15, 16, 17)(Download pdf files from the above links)
Reference Books:
1. Charles Dierbach, "Introduction to Computer Science Using Python", 1st Edition, Wiley India Pvt Ltd. ISBN-13: 978-8126556014
2. Mark Lutz, “Programming Python”, 4th Edition, O’Reilly Media, 2011.ISBN-13: 978-9350232873 3. Wesley J Chun, “Core Python Applications Programming”, 3rd Edition,Pearson Education India, 2015. ISBN-13: 978-9332555365
4. Roberto Tamassia, Michael H Goldwasser, Michael T Goodrich, “Data Structures and Algorithms in Python”,1stEdition, Wiley India Pvt Ltd, 2016. ISBN13: 978- 8126562176
5. Reema Thareja, “Python Programming using problem solving approach”, Oxford university press, 2017

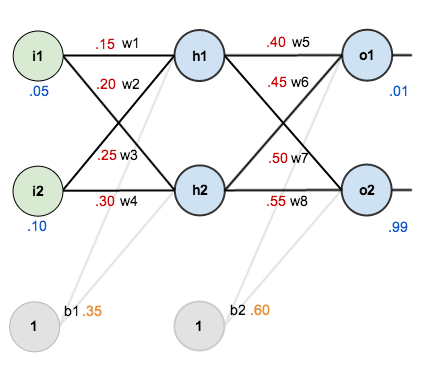
 :
:


 we get:
we get:
 :
:


 we get:
we get:
^{2}")

^{2} = \frac{1}{2}(0.01 - 0.75136507)^{2} = 0.274811083")


 . We want to know how much a change in
. We want to know how much a change in  .
. is read as “the partial derivative of
is read as “the partial derivative of  with respect to
with respect to  “. You can also say “the gradient with respect to
“. You can also say “the gradient with respect to 

^{2} + \frac{1}{2}(target_{o2} - out_{o2})^{2}")
^{2 - 1} * -1 + 0")
 = -(0.01 - 0.75136507) = 0.74136507")
") is sometimes expressed as
is sometimes expressed as 
 , the quantity
, the quantity ^{2}") becomes zero because
becomes zero because 
 = 0.75136507(1 - 0.75136507) = 0.186815602")
 change with respect to
change with respect to } + 0 + 0 = out_{h1} = 0.593269992")


 * out_{o1}(1 - out_{o1}) * out_{h1}")
 and
and  which can be written as
which can be written as  , aka
, aka  (the Greek letter delta) aka the node delta. We can use this to rewrite the calculation above:
(the Greek letter delta) aka the node delta. We can use this to rewrite the calculation above:
 * out_{o1}(1 - out_{o1})")

 so it would be written as:
so it would be written as:

 (alpha) to represent the learning rate,
(alpha) to represent the learning rate,  (eta), and
(eta), and  (epsilon).
(epsilon). ,
,  , and
, and  :
:


 ,
,  ,
,  , and
, and  .
.

 affects both
affects both  and
and  therefore the
therefore the  needs to take into consideration its effect on the both output neurons:
needs to take into consideration its effect on the both output neurons:
 :
:
 using values we calculated earlier:
using values we calculated earlier:
 is equal to
is equal to 

 , we get:
, we get:

 and then
and then  for each weight:
for each weight:
 = 0.59326999(1 - 0.59326999 ) = 0.241300709")



 * \frac{\partial out_{h1}}{\partial net_{h1}} * \frac{\partial net_{h1}}{\partial w_{1}}")
 * out_{h1}(1 - out_{h1}) * i_{1}")




